

The Attention Efficiency Newsletter Edition, Part 1
Native Sparse Attention

Introduction: Making Transformers Scale to Million-Token Contexts
I'm excited to dive into one of the most promising approaches to making large language models handle extremely long contexts efficiently. When it comes to transformer design innovations, 2025 has already seen rapid progress on various fronts, but in today's edition, we'll examine Native Sparse Attention (NSA), a breakthrough technique that rethinks how attention mechanisms work from the ground up.
As many of you running AI infrastructure might know too well, scaling transformer-based LLMs to handle long contexts isn't just about throwing more compute at the problem. It requires actually rethinking fundamental architectural choices. With NSA, DeepSeek presents a clever solution that manages to maintain model quality while dramatically reducing computation needs for sequences up to 1 million tokens long. Let's explore how it works and what it means for your AI projects.
The Fundamental Challenge: Attention Is Expensive
The core challenge NSA addresses is fundamental to large language models: the computational inefficiency of standard attention mechanisms when processing long contexts. When a transformer processes a long document (64K tokens or more), the vanilla attention mechanism becomes prohibitively expensive for two reasons:
Quadratic complexity: The computation scales as O(n²) with sequence length, meaning doubling the context length increases computation by 4x
Memory bottleneck: During autoregressive generation, the KV (key-value) cache consumes massive amounts of memory
According to the research, attention computation accounts for 70-80% of total latency when decoding with 64K context length - a massive bottleneck that limits practical applications.
The Two-Phase Problem
A critical insight about transformer inference is that it actually involves two distinct phases with different computational characteristics:
Prefilling phase: When you first input a prompt, the model processes all input tokens at once in a batched, parallelized computation. This phase is compute-bound and matrix-multiplication heavy.
Decoding phase: The model generates each new token one by one in an autoregressive manner. This phase is memory-bound, dominated by KV cache access.
Current sparse attention methods typically optimize only one of these phases. For example:
H2O optimizes decoding but requires computationally intensive preprocessing during prefilling
MInference optimizes prefilling with dynamic sparse attention but doesn't address decoding bottlenecks
This phase specialization creates a fundamental limitation: different real-world workloads have dramatically different phase dominance patterns. For a book summarization task (100K input tokens, 1K output), optimizing prefilling brings huge benefits. But for long chain-of-thought reasoning (1K input, 50K output), decoding optimization is what matters.
The NSA Approach: Three-Branch Hierarchical Attention
NSA introduces a clever three-branch approach to attention that I'd call "hierarchical sparse attention." Instead of making every query token attend to every key-value pair, NSA uses a mix of strategies to achieve efficiency without sacrificing quality:
1. Token Compression: Creating Information-Dense Summaries
The first branch works by taking continuous blocks of tokens and distilling them into more compact representations. Here's how it works:
NSA divides the sequence into blocks (typically 32 tokens per block, with a stride of 16)
Each block is processed by a learnable MLP with position encoding
This MLP condenses the entire block into a single representative key-value pair
Think of this like creating paragraph summaries of a long document. Instead of examining every word, you can first look at these summaries to get the big picture. This leads to a compressed representation that's around 1/16th the size of the original sequence.
2. Token Selection: Finding the Most Important Blocks
The second branch identifies which original blocks of tokens are most relevant to the current query:
Using attention scores from the compression branch, NSA maps importance scores to blocks of the original sequence
It selects the top-n most important blocks (typically n=16)
The query then attends to all tokens within these selected blocks
The clever part is that NSA reuses computation from the compression branch to guide this selection, minimizing overhead. This approach is both computationally efficient and hardware-friendly, as it maintains contiguous memory access patterns that modern GPUs are optimized for.
3. Sliding Window: Preserving Local Context
The third branch addresses an insight about how language models learn: they naturally find it easier to learn relationships between nearby tokens, which can dominate the learning process at the expense of long-range dependencies.
NSA solves this with a dedicated sliding window branch that:
Maintains a fixed window of the most recent tokens (typically 512)
Computes attention on this local context separately
Uses independent parameters from the other branches
This separation prevents local attention from "shortcutting" the learning of long-range patterns, forcing the model to develop specialized capabilities in each branch.
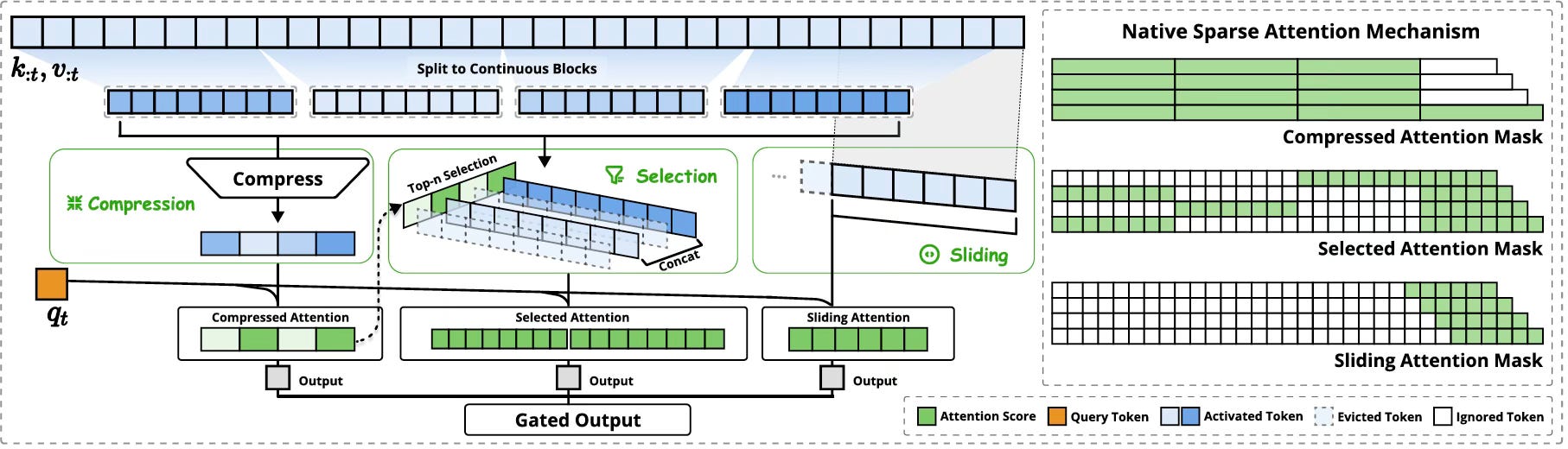
Putting It All Together: The Gating Mechanism
The outputs from these three branches are combined through a learnable gating mechanism. For each query token, the model learns to dynamically adjust how much it relies on each type of attention based on the current context. This weighted combination gives NSA extraordinary flexibility, allowing it to adapt to different types of content and reasoning tasks.
Kernel Design: Where Theory Meets Practice
The other thing that truly sets NSA apart is its focus on hardware-aligned implementation. Many sparse attention approaches look promising in theory but fail to deliver actual speedups in practice. NSA's kernel design directly addresses this gap.
The key innovation is changing how query-key-value operations are arranged in memory:
Group-Centric Data Loading: Instead of loading continuous query blocks (as FlashAttention does), NSA loads all query heads for a single position at once. Since queries at the same position (but different heads) in a GQA group share the same key-value cache, this minimizes redundant memory transfers.
Shared KV Fetching: Once all query heads for a position are loaded, NSA loads only the sparse key-value blocks needed by those queries, ensuring each block is loaded just once.
Efficient Loop Scheduling: NSA uses Triton's grid scheduler to parallelize across different query positions, maximizing GPU utilization.
This implementation achieves "near-optimal arithmetic intensity" - making efficient use of both computation resources and memory bandwidth. For real-world workloads, this translates to dramatic speedups:
9.0x forward pass speedup at 64K context length
6.0x backward pass speedup at 64K context length
11.6x decoding speedup at 64K context length
What's particularly impressive is that these speedups increase with longer sequences, with measurements showing even more dramatic gains at 1M token contexts.
Implementation Guide for Amazon P5e (H200) and Trn2 Clusters
Warning: This is more technically dense, so if you just want to know some examples of when this might be useful, skip this section.
For organizations looking to implement NSA on their AI infrastructure, here's a practical roadmap for AWS P5e instances (with NVIDIA H200 GPUs) or Amazon Trn2 instances (with AWS Trainium 2 chips):
Step 1: Framework Selection
Start with an existing transformer implementation framework that supports custom attention mechanisms:
For H200 clusters: HuggingFace Transformers with custom attention modules or PyTorch FSDP
For Trainium 2: AWS NeuronSDK with custom operators
Step 2: NSA Architecture Implementation
Implement the three core components of NSA:
Token Compression Module:
Implement the block compression function as a small MLP
Configure block size (32 tokens) and stride (16 tokens)
Set up the compression attention path
Token Selection Module:
Implement the block importance score calculation
Create the top-n selection mechanism (n=16)
Ensure blocks are properly aligned for optimal memory access
Sliding Window Module:
Implement the separate sliding window attention (window size=512)
Configure the gating mechanism to combine all three branches
Step 3: Optimized Kernel Implementation
This is the most challenging part, but crucial for real-world performance:
For H200 Clusters:
Use Triton to implement custom CUDA kernels that optimize the block-wise attention patterns
Utilize H200's 4th generation Tensor Cores which significantly accelerate matrix multiplications
Take advantage of the high-bandwidth HBM3 memory for memory-bound operations
Implement efficient kernel scheduling to maximize the utilization of the GPUs' streaming multiprocessors
For Trainium 2:
Implement custom operators using AWS Neuron SDK
Optimize for Trainium's specialized matrix multiplication units
Use the chip's on-chip memory hierarchy for efficient attention computation
Implement efficient pipeline parallelism across multiple Trainium chips
Step 4: Distributed Training Configuration
Configure your infrastructure for efficient distributed training:
Tensor parallelism across multiple accelerators for model sharding
Pipeline parallelism for very large models
Efficient attention algorithm scheduling to maximize throughput
Step 5: Progressive Optimization
For both platforms, follow an incremental approach:
First implement a functional version that correctly implements the algorithm
Profile to identify bottlenecks
Optimize the most critical kernels first
Consider hybrid approaches during transition (like NSA's suggestion of using full attention in the final layers)
Real-World Applications: Three Compelling Use Cases
Let's examine three practical applications where NSA's capabilities would provide substantial benefits over traditional transformers:
Use Case 1: Enterprise Document Search and Analysis Platform
End Goal: A comprehensive enterprise platform that enables employees to search across, analyze, and extract insights from the company's entire document repository - including contracts, technical documentation, research papers, meeting transcripts, and historical reports. The system would allow users to ask complex questions that might require understanding connections between information scattered across multiple documents or sections written months or years apart.
For example, a user could ask: "What technical approaches did we consider for solving the cooling problem in our 2020 product line, and how did those compare to the solutions we implemented in our 2023 models?" The model would need to retrieve, understand, and synthesize information from documents spanning years.
Training Data:
The training data would consist of:
Millions of internal company documents (contracts, reports, specifications)
Technical documentation spanning multiple product generations
Meeting transcripts and research notes
Industry publications and technical standards relevant to the company's field
Email threads and project management documentation
Each training example would typically be 20K-50K tokens in length, combining multiple related documents to form a coherent context. Supervised fine-tuning would include queries paired with human-expert answers that demonstrate effective cross-document reasoning.
Benefits of NSA for this application:
Cost Efficiency: Training on 50K token contexts with full attention would be prohibitively expensive. NSA reduces training costs by 6-9x.
Real-Time Inference: Employee queries need responses in seconds, not minutes. NSA's faster decoding enables practical real-time use with full context.
Enhanced Accuracy: NSA's architecture encourages the model to identify and focus on the most important sections across documents, improving retrieval quality.
Use Case 2: Clinical Decision Support System
End Goal: A specialized medical AI assistant that helps healthcare providers analyze patient history, current symptoms, lab results, and relevant medical literature to suggest potential diagnoses and treatment options. The system would ingest a patient's complete medical history (potentially spanning decades), current presenting information, and relevant medical knowledge to provide evidence-based recommendations to physicians.
The model could analyze a 30-year patient history alongside recent test results and produce an analysis like: "Based on the patient's history of recurrent infections at ages 5, 12, and 28, combined with current elevated inflammatory markers and the specific pattern of symptoms, consider investigating for CVID (Common Variable Immune Deficiency), which was not previously diagnosed but matches 85% of the presentation pattern."
Training Data
The training data would include:
De-identified patient electronic health records (EHRs) with full longitudinal histories
Medical literature, textbooks, and peer-reviewed research papers
Clinical guidelines and standard treatment protocols
Case studies of rare conditions and their varying presentations
Medication information including interactions, contraindications, and effectiveness studies
Medical imaging reports and laboratory test interpretations
Typical training examples would range from 16K to 64K tokens, including full patient histories alongside relevant medical literature sections. Fine-tuning would involve physician-annotated cases with proper diagnostic reasoning and treatment recommendations.
Benefits of NSA for this application:
Comprehensive Analysis: Unlike systems that truncate medical histories, NSA can process complete patient records spanning decades.
Pattern Recognition: The hierarchical attention mechanism helps identify connections between symptoms or events separated by years, potentially revealing patterns that conventional models might miss.
Explainability: The block selection mechanism provides natural attention visualization, showing physicians which parts of the record influenced a recommendation - critical for building trust and meeting regulatory requirements.
Use Case 3: Code Intelligence Platform for Software Development
End Goal: A comprehensive code intelligence platform that understands entire codebases (not just individual files) to assist developers with complex tasks like architecture recommendations, bug detection, security vulnerability identification, and automated refactoring. The system would analyze entire repositories including source code, configuration files, documentation, and version control history to provide contextually aware development assistance.
For example, a developer could ask: "Identify potential performance bottlenecks in our payment processing pipeline and suggest refactoring approaches that maintain compatibility with our existing API contracts." The model would analyze the entire codebase to provide holistic recommendations.
Training Data
The training data would consist of:
Complete open-source repositories across various programming languages and domains
Internal codebases (for company-specific deployments)
Technical documentation, comments, and architectural design documents
Code review discussions and issue tracker histories
Test suites and their coverage reports
API specifications and dependency information
Commit histories showing code evolution
Training examples would typically span 32K-128K tokens, containing entire modules or service implementations rather than isolated files. Fine-tuning would include developer-solved problems showing proper reasoning about complex codebase interactions.
Benefits of NSA for this application:
Repository-Level Understanding: NSA enables processing entire repositories (100K+ lines of code) as a single context, rather than isolated files.
Reference Resolution: The multiple attention branches maintain awareness of dependencies, inheritance hierarchies, and function calls across files.
Memory Efficiency: Code intelligence tools often need to run locally on developer machines. NSA's reduced memory footprint makes this feasible even for large projects.
Conclusion: The Path Forward for Efficient Attention
NSA represents a significant advancement in making transformers more efficient for long-context processing. By combining hierarchical sparse attention with hardware-aligned implementation, it achieves dramatic speedups without sacrificing model quality - and in some cases, even improving it.
What makes NSA particularly compelling is its practicality. Unlike many research approaches that remain theoretical, NSA demonstrates real-world speedups and provides a clear implementation path. Its native trainability means organizations can realize benefits throughout the entire model lifecycle, from pretraining through deployment.
In my next two newsletters, I'll explore complementary approaches that further push the boundaries of efficient attention. We'll look at:
Mixture of Block Attention (MoBA), which applies MoE principles to attention mechanisms, enabling dynamic routing of queries to only the most relevant blocks.
LightThinker, a method that enables models to dynamically compress their intermediate thoughts during reasoning, significantly reducing the token overhead in chain-of-thought applications.
Until then, if you're working with long-context applications, NSA offers a compelling path to improved efficiency today. The combination of its hierarchical attention approach and hardware-aligned implementation makes it an excellent candidate for organizations looking to scale their language models to million-token contexts without proportional increases in compute costs.