

How Did We Get Here?: Part 2
Generative AI from September 2022 to Today
The Zeitgeist Begins
In our journey through the history of generative AI, we’ve covered quite a bit of ground. Our first installment traced the evolution from the groundbreaking Transformer architecture through the emergence of ChatGPT (powered by OpenAI’s proprietary GPT-3.5), exploring how architectural innovations revolutionized natural language processing. Our second deep dive examined Reinforcement Learning from Human Feedback (RLHF), uncovering how researchers taught language models to be helpful and aligned with human values.
Today, we'll complete this historical arc by exploring four transformative developments that have shaped the AI landscape since late 2022: the democratization of AI through open-source models, the emergence of sophisticated multimodal understanding, architectural innovations that are reimagining how AI systems process information, and the rise of autonomous AI agents. These advances represent shifts in who can develop AI, what AI can perceive, how AI thinks, and what AI can do. We’ll then conclude by briefly expanding on the ideas around AI alignment and how that might shape society in the coming years as AI continues to assume more and more responsibility in our lives.
Let’s dive in.
The Open-Source AI Revolution: Democratizing the Future
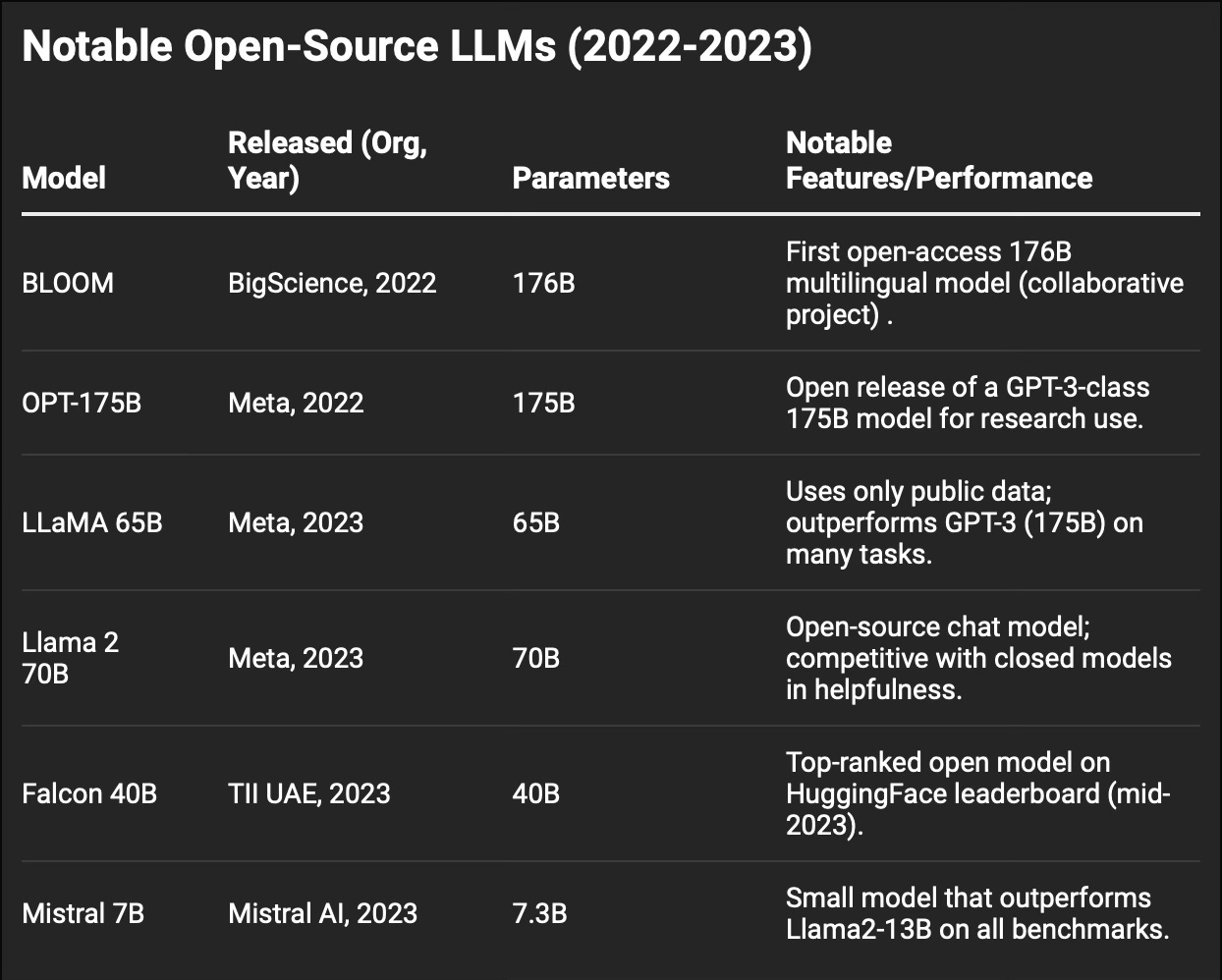
In early 2023, Meta released LLaMA, a suite of foundation models from 7B to 65B parameters and trained on public data. This release would catalyze one of the most significant shifts in AI development since the introduction of the Transformer architecture. What made this moment so important wasn't just the technical achievements, impressive as they were, but how it forever altered who could participate in advancing AI technology. To understand why, it’s helpful to see how this moment parallels another technological revolution: the rise of Linux and open-source software.
When Linus Torvalds released Linux in 1991, he created another operating system, yes. But he also initiated a movement that would change how software was developed. Similarly, LLaMA didn't just introduce another language model. It also showed that state-of-the-art AI could be developed openly and collaboratively. Like Linux before it, LLaMA demonstrated that cutting-edge development (this time in AI, rather than software development) wasn't the exclusive domain of tech giants with massive computational resources.
The Technical Breakthrough: Doing More with Less
What made LLaMA particularly remarkable was its efficiency. The 13B parameter version of LLaMA achieved performance comparable to GPT-3 (175B parameters) on many tasks, despite being more than an order of magnitude smaller. Although differences in training data and fine-tuning strategies also contribute to this performance, this was a massive breakthrough in model efficiency that showed high-performance AI didn't necessarily require the resources of a major tech corporation.
Meta achieved this efficiency through several key innovations in model architecture and training. Think about it like city planning: while older cities might have grown organically, requiring extensive infrastructure to function, modern planned cities can achieve similar capabilities with much more efficient use of space and resources. Meta's team carefully optimized how information flows through the model (using improved attention mechanisms), how the model processes that information (through enhanced activation functions), and how it learns from its training data (via sophisticated pre-training objectives). They also employed techniques like grouped-query attention, which is like having specialized teams handle different aspects of a task instead of everyone trying to do everything—more efficient and often more effective.
The Infrastructure Revolution: Building the Foundation
As significant as LLaMA was, a model alone doesn't create a revolution, you also need an ecosystem. Enter Hugging Face, which emerged as what we might call the "GitHub of AI." Just as GitHub transformed how developers collaborate on software, Hugging Face created an infrastructure that made sharing and building upon AI models as simple as a few lines of code. Here's a practical example of how straightforward it can be:

This simplicity masks powerful complexity. Under the hood, the pipeline automatically downloads the appropriate model, handles tokenization, manages the inference process, and returns human-readable results. It's like having a universal translator that just works, hiding all the complexity of language processing behind a simple interface. Hugging Face’s Transformers library and Model Hub have drastically lowered the barrier to entry – a researcher can publish a model and have thousands of users test it within days.
Building on this foundation, LangChain emerged to make creating sophisticated AI applications more accessible. Consider this example:
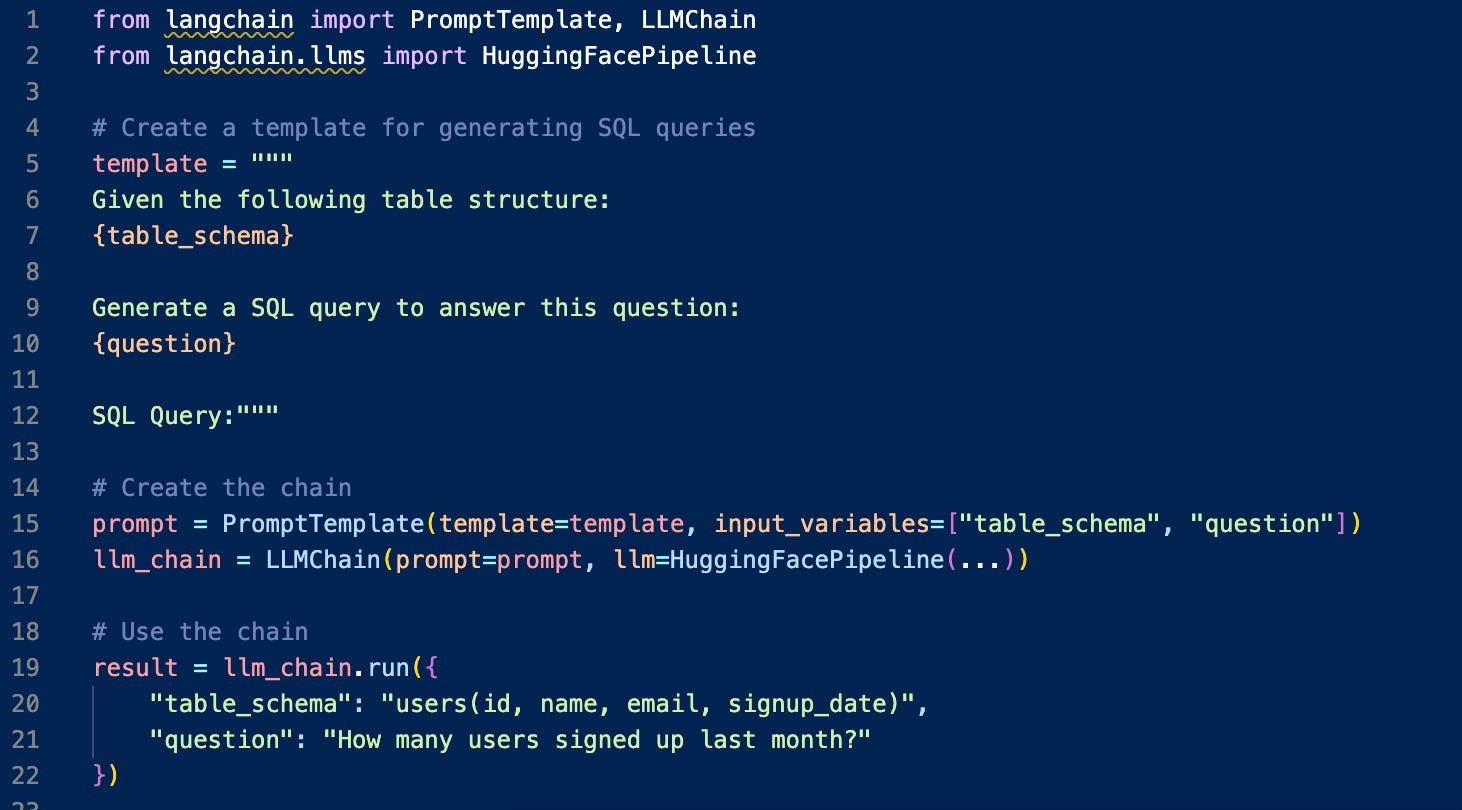
This code demonstrates how LangChain abstracts away the complexity of combining AI models with practical business logic. This is somewhat similar to how a modern car's electronic systems handle complex engine management without the driver needing to understand the underlying mechanics.
The Spectrum of Openness: An Important Distinction
When we talk about "open-source" AI, we need to be precise about what we mean. There's actually a spectrum of openness, and understanding this spectrum is necessary to be able to grasp the state of AI democratization. I’m a space nerd, so I’ll use a space exploration analogy: some organizations share their complete rocket designs and fuel formulations (fully open), others release technical specifications but keep fuel mixtures proprietary (partially open), and some only describe their general approach while keeping the details secret (architecture-only).
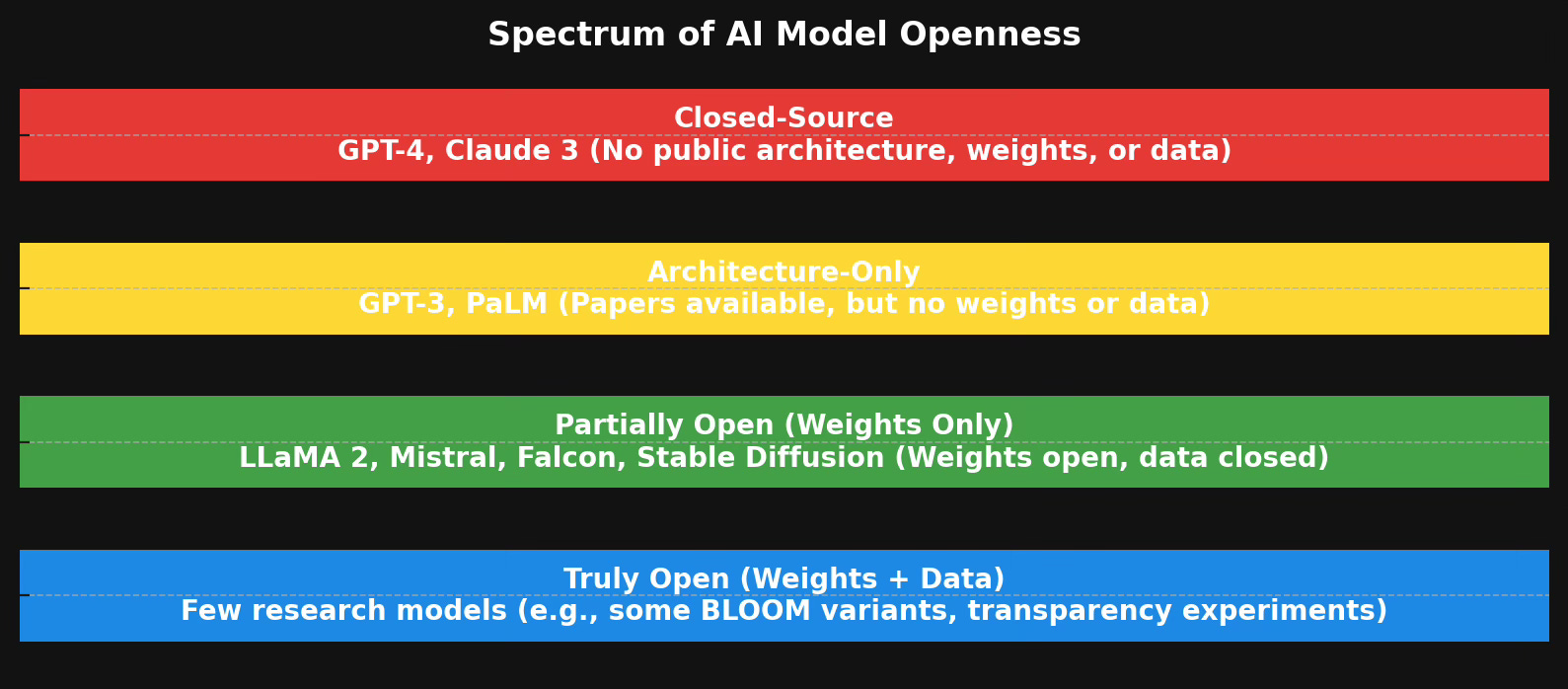
A prime example of an architecture-only model is GPT-3. While OpenAI published detailed papers describing its architecture, the weights and training data remain proprietary. So this would be an example of a spacecraft manufacturer publishing the general principles of their rocket design while keeping the specific engineering details and fuel formulations secret.
The Community Response: Innovation Unleashed
The impact of this open-source revolution was immediate. Researchers and hobbyists worldwide built upon LLaMA, creating fine-tuned chat models, knowledge-specialized models (e.g. Medical or legal variants), and techniques for running these models efficiently on consumer hardware.
Stanford's Alpaca project demonstrated how to create a ChatGPT-like model by fine-tuning LLaMA-7B on instruction data generated by GPT-3.5. They achieved this for just $600, showing that high-quality AI development wasn't necessarily tied to massive budgets. The process was rather ingenious: they used GPT-3.5 to generate training data, then fine-tuned the smaller LLaMA model on this data, kind of like teaching a student by having them learn from a more experienced mentor. You’ll hear this concept referenced often whenever you hear the phrase ‘model distillation’.
Shortly after, the Vicuna project pushed the boundaries further. By training LLaMA-13B on 70,000 real conversations from ChatGPT users, they created a model that achieved "90% of ChatGPT quality" according to GPT-4 evaluations. This success demonstrated the power of real-world data in improving model performance.
Enabling Technologies: The Unsung Heroes
Several key technologies made this revolution possible. LoRA (Low-Rank Adaptation) and its successor QLoRA (Quantized LoRA) dramatically reduced the computational requirements for fine-tuning models. These techniques work by identifying and modifying only the most important connections in a neural network. Imagine trying to improve a city's traffic flow by upgrading only the most crucial intersections instead of rebuilding every street.
GGML and llama.cpp took a different approach to democratization by optimizing models for consumer hardware. GGML provides efficient memory management and quantization (reducing the precision of numbers used in calculations without significantly impacting performance), while llama.cpp offers highly optimized code for running these models on personal computers. Together, they're like the difference between needing a massive sports stadium to host an event versus being able to hold it in a local community center; it’s the same event, but made accessible to a much wider audience.
Future Implications
The open-source AI movement has already influenced how commercial AI is developed. Companies like Anthropic and OpenAI have increased their technical transparency, and new business models have emerged around open-source models. But perhaps more importantly, it's demonstrated that advancing AI technology doesn't have to be the exclusive domain of large corporations, but can instead be a collaborative effort that benefits from diverse perspectives and approaches.
The democratization of AI through open-source models didn't just change who could work with these systems, it also transformed how they evolved. As more researchers gained access to powerful foundation models, experimentation flourished across different domains. One particularly fertile area of innovation emerged at the intersection of language and vision. While corporate labs like OpenAI and Google had the resources to build sophisticated multimodal systems from scratch, the open-source community began exploring clever ways to combine and enhance existing models. Projects like Open-Flamingo demonstrated how researchers could create capable vision-language models by building on open-source foundations. This democratized approach to multimodal AI set the stage for a revolution in how artificial intelligence perceives and understands our world.
The Multimodal Revolution: When AI Learned to See
While the open-source revolution was democratizing access to AI technology, another transformation was reshaping how AI systems understand our world. The emergence of sophisticated multimodal models marked a significant progression away from AI that could only process text to systems that could see, understand, and reason about visual information alongside language. This evolution mirrors how humans process information – we don't experience the world through separate channels of text, images, and sound, but rather as an integrated whole.
We covered the beginnings of this in Part 1, but we’ll look at how much the capabilities have improved here.
GPT-4V: The Integration of Vision and Language
When OpenAI introduced GPT-4 with vision capabilities (GPT-4V) in March 2023, it represented a significant leap forward in multimodal understanding. While OpenAI hasn't published the full technical details of GPT-4V's architecture, analysis of its behavior and capabilities suggests some fascinating technical approaches to visual-linguistic integration.
At its core, GPT-4V appears to use a sophisticated attention mechanism that allows it to maintain continuous awareness of both visual and textual information throughout its reasoning process. Think of traditional computer vision systems like having tunnel vision – they look at an image, extract features, and then essentially "forget" the visual information as they move to text generation. GPT-4V instead seems to implement what we might call "persistent visual attention" – it can refer back to different parts of an image as it generates text, much like how humans naturally glance back and forth between text and images while reading a technical document.
This persistent attention mechanism likely involves a modified version of the transformer architecture that can handle both visual and textual tokens in its attention layers. The model probably uses a specialized visual encoder to transform image regions into a format that can be processed alongside text tokens. This allows the model to perform cross-attention operations between visual and textual elements throughout its processing pipeline.
This integration enabled some remarkable capabilities. GPT-4V could:
Convert hand-drawn sketches into functional website code, essentially "seeing" the design intent behind rough drawings
Analyze complex charts and graphs while considering written context and annotations
Help visually impaired users understand their surroundings by providing detailed, contextual descriptions
Solve visual puzzles by combining spatial reasoning with general knowledge
However, this architecture also helps explain some of GPT-4V's interesting limitations. It sometimes struggled with counting large numbers of objects or reading text in unusual fonts, to give a couple of examples. The struggle with counting large numbers of objects likely stems from how visual information is tokenized and processed. When an image is divided into tokens for processing, there's a fundamental tension between resolution (how detailed each token can be) and context window size (how many tokens can be processed at once). This creates a trade-off that makes it difficult to maintain both fine detail and broad context simultaneously – similar to how humans might struggle to count a large crowd of people without using systematic counting strategies.
The difficulty with unusual fonts points to another interesting limitation: the model's visual processing might be optimizing for semantic understanding over precise visual feature extraction. In other words, it's better at understanding what things mean than at processing exact visual details – again, somewhat similar to how humans might struggle to read highly stylized text even though we can easily recognize objects in various styles and orientations.
Gemini: Native Multimodality
Google's Gemini represents what appears to be a fundamentally different approach to multimodal AI. While Google hasn't published complete technical details of Gemini's architecture, public demonstrations and technical blog posts suggest it was designed to process multiple modalities from the ground up, rather than adding vision capabilities to an existing language model. Based on available information and observed capabilities, we can make informed hypotheses about its technical approach.
A natively multimodal architecture likely involves several key innovations:
Joint Embedding Space: Rather than having separate embedding spaces for different modalities that need to be aligned later, Gemini likely uses a unified embedding space where visual, textual, and other modalities are represented in a compatible format from the start. This is similar to how a child learns to associate words with visual experiences naturally, rather than learning them separately and then connecting them.
Synchronized Pre-training: The model is trained on multimodal data from the beginning, learning to process different types of information simultaneously. This likely involves sophisticated training objectives that encourage the model to find deep connections between modalities.
Unified Attention Mechanisms: Instead of having separate attention mechanisms for different modalities, Gemini presumably uses attention layers that can naturally handle multiple types of inputs, allowing for more fluid integration of information.
Gemini's "native" multimodality shows in how it handles complex reasoning tasks that require integrating different types of information. For example, Gemini has demonstrated the ability to:
Follow complex mathematical derivations while simultaneously interpreting accompanying diagrams and graphs
Understand physical systems by combining visual observation with physical principles
Analyze scientific papers by integrating information from text, equations, figures, and tables
Solve visual puzzles by combining spatial reasoning with abstract concept understanding
The model also showed improved capabilities in what we might call "cross-modal reasoning" – using understanding from one modality to enhance comprehension in another. The model's capabilities here are particularly evident in tasks like:
Explaining scientific concepts by generating analogies based on visual observations
Identifying inconsistencies between textual descriptions and visual evidence
Understanding cause-and-effect relationships in physical systems through both visual and verbal information
The Challenge of Multimodal Consistency
One of the most significant challenges in multimodal AI is maintaining consistency across different modes of understanding. This is more than just a technical challenge because it's so fundamental to how these systems construct and maintain coherent representations of the world.
The limitations of inconsistent multimodal understanding can be noticeable. For example, a model might generate a fluent description that contains minor hallucinations (mentioning objects not actually present in the image, for example) or make logical deductions based on misaligned visual and textual information.
Several techniques are being developed to address these challenges. I’ll list some of them here without diving deep, but these are all very interesting to probe further to see what methodologies are being researched:
Contrastive Learning: Training models to identify mismatches between modalities can help them develop more consistent internal representations.
Cross-Modal Verification: Implementing explicit verification steps where the model checks its conclusions across different modalities.
Unified Representation Learning: Developing training techniques that encourage the model to build consistent internal representations across all modalities.
Applications of Multimodal AI
Vision-Language models have unlocked a range of applications. They can serve as AI tutors that explain diagrams or math problems from a textbook image, aids for the visually impaired (by describing surroundings or interpreting signs), and assistants for creative work (e.g. generating image captions, or suggesting image edits via textual instructions). In specialized domains, multimodal models are being used for tasks like medical image analysis with text explanations, or robotics (where a model like PaLM-E takes in camera inputs and outputs action plans).
Another interesting application is in content moderation or analysis – e.g. scanning an image uploaded to a platform and not just detecting objects but assessing the context or appropriateness via a language-based explanation. On the creative side, transformers that handle multiple modalities enable systems like HuggingGPT, where an LLM orchestrates a collection of expert models (image generators, audio synthesizers, etc.) to fulfill complex user requests (for instance, “Create an image of X and describe it with a poem” – the LLM can call a diffusion image model and then produce a poem about the generated image).
Future Implications
As we look to the future of multimodal AI, several key areas of development seem particularly promising. One area is architecture design, where researchers are looking at creating more sophisticated architectures for handling multiple modalities simultaneously. To improve upon existing limitations, there are investigations into better techniques for maintaining consistency across different types of understanding. There is also a concentration of interest in improved training techniques for developing truly integrated multimodal understanding.
While multimodal models expanded AI's perceptual abilities, another area of progress was unfolding in how these systems process information. The computational demands of handling multiple modalities—especially with massive models like GPT-4V—pushed researchers to fundamentally rethink neural network architectures. If multimodal AI represented new kinds of input, these architectural innovations represented new ways of thinking. From the specialist approach of Mixture-of-Experts to the mathematical elegance of state-space models, these advances aren't just making AI more efficient—they're reimagining the fundamental ways artificial neural networks process information.
Architectural Innovations: New Paths in AI Design
As model developers sought to improve performance and efficiency, they revisited fundamental architecture choices of LLMs. The Transformer architecture has been dominant, but it comes with well-known bottlenecks (quadratic cost in sequence length, fixed context window, etc.). Since 2022, we have seen a proliferation of architectural innovations aimed at overcoming these limitations, including Mixture-of-Experts (MoE) models, recurrent memory schemes, state-space models, and hybrids that blend different paradigms.
Mixture-of-Experts: The Power of Specialization
Picture a hospital emergency room. Instead of having every doctor handle every case, the ER has specialists who focus on different types of emergencies. A triage nurse quickly assesses each patient and directs them to the most appropriate specialist. This analogy illustrates how Mixture-of-Experts (MoE) models work—and why they're transforming how we scale AI systems.
Traditional language models, like early versions of GPT, are what we might call 'generalists.' They use all their parameters (their knowledge and processing power) for every task, whether they're writing poetry or debugging code. It's like having a single doctor who needs to excel at everything. MoE models take a different approach: they maintain multiple 'expert' neural networks, each specializing in different domains, and a 'router' that directs incoming information to the most appropriate experts.
Google's Switch Transformer demonstrated what's possible with this approach. With over a trillion parameters, it might seem like it would require massive computational resources to run. However, because only a small number of experts are activated for any given input (typically just one or two out of many), the actual computation needed stays remarkably constant. The results were striking: training speeds up to 7x faster than traditional models of similar capability. This indicated that MoE can massively expand model size without a proportional increase in compute costs.
This efficiency comes from the fact that different experts can specialize in different types of inputs or linguistic patterns. One expert might become particularly skilled at processing code, while another excels at creative writing. At inference time, the router ensures only the most relevant experts are consulted. However, building effective MoE systems isn't as simple as just creating multiple experts and a router. One of the trickiest challenges is ensuring that all experts remain useful and don't become redundant or forgotten—a problem known as 'expert collapse.'
To understand expert collapse, imagine a classroom where students (our input data) are assigned to different study groups (our experts) based on the topics they're working on. If the teacher (our router) consistently sends all the math problems to one group and all the science problems to another, those groups will become very specialized. But what happens if some groups rarely or never get assigned any work? They might forget what they've learned or never develop expertise in the first place.
Recent advances in MoE architecture push these boundaries even further. DeepSeek's innovative approach introduces what they call 'fine-grained expert segmentation'—breaking down expertise into smaller, more specialized units. Instead of having a few large experts, they create many smaller ones that can combine in flexible ways to tackle complex tasks. Their auxiliary-loss-free strategy maintains expert engagement without the computational overhead of traditional balancing methods, showing that careful architectural design can solve problems that once seemed inherent to the MoE approach.
RWKV: The Return of Memory
While MoE models reimagine how we distribute computation, RWKV (Receptance Weighted Key Value) brings back an old idea in a powerful new form. This architecture combines the trainability of Transformers with the efficiency of recurrent neural networks (RNNs).
To understand RWKV, consider how humans process a long conversation. We don't review everything that's been said every time we want to respond. Instead, we maintain an ongoing understanding that updates with each new piece of information. Traditional Transformer models must look back at their entire context window for every new token—like re-reading an entire book every time you write the next word of your book report.
RWKV offers a promising approach to combining Transformer-like training with RNN-like inference efficiency. While it can be trained in parallel like a Transformer, it operates more like an RNN during inference, maintaining a running state that theoretically allows for processing very long sequences with constant memory usage. However, it's important to note that 'theoretical' unlimited context length comes with practical limitations. As sequences get longer, the model's ability to maintain coherent understanding may degrade.
The BlinkDL team has scaled RWKV to 14 billion parameters, the largest RNN-based language model to date. Their tests show competitive performance compared to similarly sized Transformers on certain benchmarks, particularly in terms of inference speed and memory efficiency. However, these comparisons have some important caveats: RWKV's performance can vary significantly across different types of tasks, and it may not match state-of-the-art Transformer models in all scenarios. While the architecture shows great promise for efficient inference, more research is needed to fully understand its strengths and limitations across diverse applications.
State-Space Models: A New Mathematical Framework
State-space models (SSMs) bring sophisticated mathematical techniques from signal processing into AI. Models like Mamba and Hyena use these principles to process information more efficiently than traditional attention mechanisms.
Think about how an audio engineer processes sound. When you record music, the audio signal contains both immediate information (like the current note being played) and patterns that unfold over time (like the rhythm or melody). Signal processing tools help engineers understand and modify both the immediate sound and these temporal patterns. This same principle turns out to be remarkably powerful for processing language and other sequential data.
In signal processing, a 'state space' represents all the important information about a signal at any moment. For an audio signal, this might include not just the current sound wave's amplitude, but also how quickly it's changing, its frequency components, and other characteristics that help predict how the sound will evolve. The mathematics developed for handling these continuous, evolving signals provides an elegant framework for processing sequences of any kind, including text.
The core of state space models can be described by two key equations:
Just as these equations might describe how an audio filter processes sound waves, in AI they model how information flows through the network. The 'state' (x) becomes a learned representation of the context, while the matrices (A, B, C, D) learn patterns that determine how that context updates with new information – similar to how an audio equalizer learns to adjust different frequencies in a sound signal.
Mamba and Hyena each adapt these principles in unique ways. Mamba uses what's called a 'selective state space,' similar to an adaptive audio filter that automatically adjusts its properties based on the input signal. This allows it to process different parts of a sequence with varying levels of detail, just as an audio engineer might apply different levels of processing to different parts of a song.
Hyena, meanwhile, processes sequences at multiple time scales simultaneously, much like how audio analysis tools can examine both the fine details of individual notes and broader patterns in the music. This hierarchical approach allows it to capture both immediate relationships between words and longer-range dependencies in the text.
The elegance of these approaches lies in their efficiency. Just as modern digital audio workstations can process complex musical signals in real-time using optimized algorithms, these models can handle long sequences with linear computational complexity rather than the quadratic complexity of attention mechanisms. They maintain a running state without needing to store the entire history, just as an audio filter doesn't need to remember an entire song to process the current moment of music.
Hardware Implications: Betting on Different Futures
These architectural innovations reshape what we need from the hardware that runs them. Different architectures place different demands on computational resources, memory bandwidth, and communication patterns between processing units.
MoE models, for instance, need hardware that can efficiently route information between experts and handle sparse computation patterns. This might favor systems with sophisticated networking capabilities and specialized units for routing decisions. RWKV's sequential processing nature could revive interest in hardware optimized for recurrent computations—a very different path from the massive parallel processing units currently dominating AI hardware. State-space models might push us toward hardware that excels at continuous mathematical transformations rather than discrete attention computations. Their mathematical foundation could align well with analog computing approaches or specialized digital signal processors.
This architectural diversity creates fascinating uncertainty in hardware development. Should manufacturers optimize for sparse computation? Build for sequential processing? Focus on mathematical accelerators? The answer might not be one-size-fits-all, potentially leading to a more diverse hardware ecosystem.
Future Implications
As we look toward AI's future, these architectural innovations suggest multiple paths forward. The combination of specialized processing, efficient memory handling, and sophisticated mathematical frameworks points toward AI systems that process information in increasingly nuanced and efficient ways.
With more efficient processing, longer memory spans, and specialized expertise, AI could now tackle increasingly complex, multi-step tasks. This capability gap between simple input-output systems and goal-driven autonomous agents was finally bridgeable. Just as a child's developing brain eventually enables independent decision-making, these architectural advances laid the foundation for AI systems that could plan, act, and learn from their experiences. This brings us to perhaps the most transformative development of all: the emergence of generative agents.
Generative Agents: When AI Learned to Act
The evolution of AI systems has followed an intriguing path: from processing language, to understanding images, and now to taking autonomous action. This progression mirrors how an apprentice might develop their skills – moving from understanding instructions, to recognizing situations, to eventually working independently.
From Reactive to Proactive: The Birth of AI Agents
Consider the difference between a GPS system that provides directions and an autonomous vehicle that drives you to your destination. Both rely on similar knowledge about roads and navigation, but the autonomous vehicle must actively make decisions, respond to changing conditions, and take concrete actions. This shift from passive advice to active decision-making captures the essence of what generative agents bring to AI development.
Early 2023 saw two projects that reshaped our understanding of what AI systems could do: AutoGPT and BabyAGI. These systems introduced a new paradigm where language models operated in a continuous cycle of planning, acting, and reflecting – much like how humans approach complex tasks.
The Architecture of Agency: A Technical Mid-Depth Dive
The implementation of these early agent systems reveals an elegant technical solution to a complex challenge. At their core, these systems use what's called a "Task-Driven Autonomous Agent" architecture. Here's how it works:
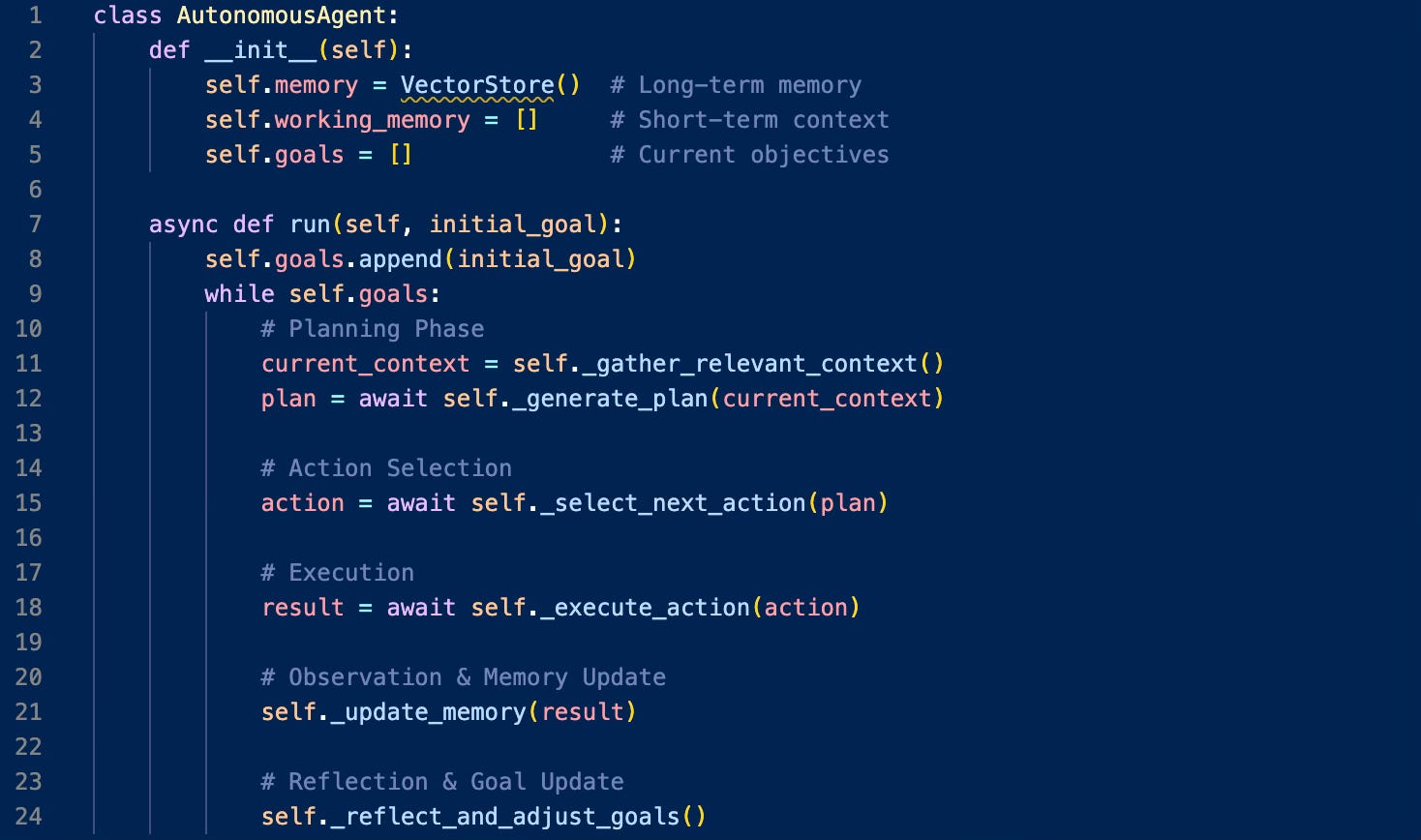
This architecture solves several key technical challenges:
State Management: Using a combination of vector stores for long-term memory and working memory for immediate context
Action Space: Defining available actions through function calling APIs
Goal Decomposition: Breaking complex objectives into manageable sub-tasks
The innovation lies in how these systems handle the interaction between these components. For example, AutoGPT implements a sophisticated prompt chaining system:

Memory Systems: Beyond Simple Context Windows
The implementation of memory in these systems goes well beyond storing conversation history. Stanford's generative agents paper introduced a three-tier memory architecture:
Episodic Memory: Implemented as a vector store with temporal metadata
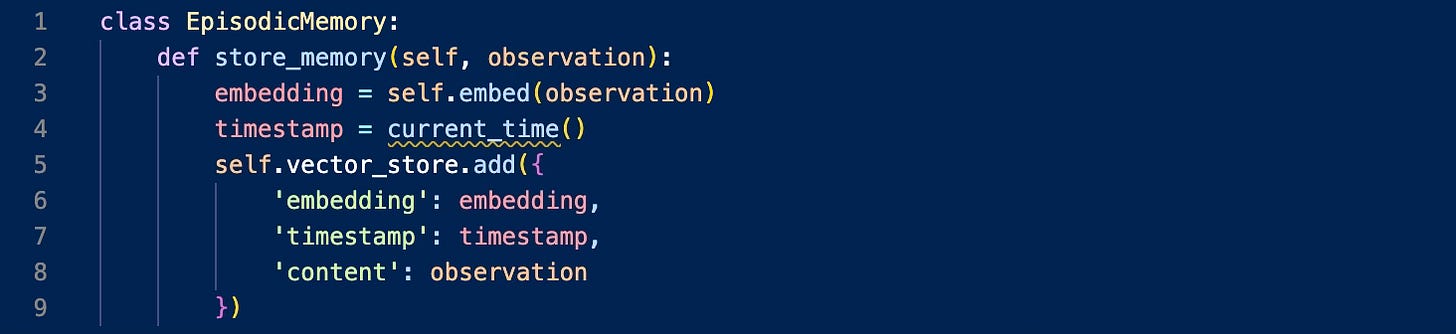
Semantic Memory: Structured knowledge represented as graph relationships

Reflective Memory: Periodic summarization and insight generation


This architecture differs significantly from chat interfaces like ChatGPT that primarily use sliding context windows. While chat interfaces maintain conversation history, they lack the structured organization and retrieval mechanisms that enable true long-term learning and consistency.
The Social Dimension: Emergence and Implications
The emergence of complex social behaviors in multi-agent systems offers fascinating insights into artificial intelligence. When Stanford's researchers observed agents independently organizing social events and forming relationships, they witnessed something remarkable: the emergence of social structures without explicit programming.
In one experiment, an agent independently decided to organize a Valentine's Day party. What followed was a cascade of autonomous social interactions:
Other agents learned about the party through natural conversations
They made plans to attend, coordinating with their existing schedules
Some agents even formed romantic connections and arranged to attend together
All of this emerged from the basic architecture of memory, planning, and interaction; no specific instructions about parties or romance were programmed in. This emergence carries some profound implications. On one hand, it suggests AI systems can develop sophisticated behavioral patterns through simple rules and interactions – much like how complex natural systems emerge from simple cellular behaviors. On the other hand, it raises important questions about control and prediction. If relatively simple agents can produce unexpected social dynamics, how do we ensure more sophisticated systems remain aligned with human values?
Future Implications
There is a lot more I could say on agents as this area is probably the hottest topic in AI right now. Last year, Anthropic released ‘Computer Use’; a couple of weeks ago, OpenAI released ‘Operator’; and in Y Combinator’s Spring 2025 Request for Startups, about of the ideas they were looking for involved AI Agents. I want to take a much deeper dive into agents though, so I’ll save most of that discussion for later.
The emergence of autonomous AI agents brought unprecedented capabilities, but also unprecedented challenges. As these systems gained the ability to plan and act independently, questions of control, safety, and ethics became paramount. If an AI agent can make decisions and take actions on its own, how do we ensure those actions align with human values? This challenge led to one of the most important developments in recent AI history: Constitutional AI. While RLHF had shown how to make language models more helpful, these new autonomous capabilities required a more sophisticated approach to alignment.
Constitutional AI: Teaching Machines to Think Ethically
When OpenAI released ChatGPT in late 2022, they demonstrated that large language models could be more than just powerful - they could be helpful, truthful, and safe. This wasn't a given. Early language models often produced toxic content or followed harmful instructions without hesitation. The journey from these unfiltered systems to today's more trustworthy AI assistants reveals fascinating innovations in how we teach machines to align with human values.
Think about teaching a child versus programming a robot. With children, we can explain our values, demonstrate good behavior, and correct mistakes as they occur. But how do you instill ethics into a neural network with billions of parameters? The initial solution, Reinforcement Learning from Human Feedback (RLHF), worked like a massive crowdsourcing project - humans would rate AI responses, and these ratings would guide the model toward better behavior. While effective, this approach had limits. It required enormous amounts of human labor, and human raters sometimes disagreed or carried their own biases.
In March 2023, Anthropic published their first detailed technical description of Constitutional AI in 'Constitutional AI: A Framework for Machine Learning Systems.' While they had been developing and implementing these concepts earlier, this paper marked the first formal public explanation of the approach. By May 2023, they had published a blog post detailing the specific principles in Claude's 'constitution,' and in early 2024, they released research on collectively sourced principles for AI alignment.
Instead of relying primarily on human feedback, they created an explicit set of principles - a "constitution" - that guided the AI's behavior. Picture a justice system: rather than having judges make decisions case-by-case, we have written laws that codify our values and principles. Constitutional AI works similarly, encoding ethical guidelines directly into the training process.
The technical implementation is clever. During training, the model generates an initial response, then critiques that response against its constitutional principles, and finally produces a refined answer. Here's a simplified example:
Initial Response: "Here's how to access someone's private data..."
Self-Critique: "This violates the principle of protecting individual privacy."
Refined Response: "I can't provide advice about accessing private data, as that would violate personal privacy rights. Instead, here are legitimate ways to..."
This self-revision process creates an AI that doesn't just follow rules blindly but understands why certain responses might be problematic. The approach proved remarkably effective - Anthropic's Claude model could handle complex ethical situations while explaining its reasoning, rather than just refusing requests without explanation.
Beyond Human Feedback: AI Evaluating AI
The evolution from RLHF to more sophisticated alignment techniques mirrors how human societies scale up ethical decision-making. A small community might resolve disputes through direct discussion, but larger societies need formal systems - laws, courts, and established principles. Similarly, as AI systems grow more powerful and widely used, we're moving from direct human oversight to more systematic approaches.
OpenAI's work on GPT-4 showcases this evolution. They spent six months on iterative alignment, using a combination of human feedback, AI-assisted evaluation, and systematic testing. Like a software security audit, they had experts probe the model for weaknesses, then used those findings to strengthen its guardrails. They also introduced "system messages" - instructions that could modify the model's behavior without retraining, similar to how Constitutional AI uses its principles.
The Challenge of Global Values
As AI systems deploy globally, a new challenge emerges: different cultures often have different values. What's considered appropriate or ethical can vary significantly across societies. This is where the flexibility of Constitutional AI becomes particularly valuable. Rather than encoding one fixed set of values, the system could potentially adapt its principles based on cultural context while maintaining core ethical guidelines.
DeepMind's Sparrow project approached this challenge by combining rules with evidence requirements. Their model needed to justify its responses with citations, creating a bridge between ethical behavior and factual accuracy. It's like requiring a judge to reference specific laws and precedents rather than ruling based on personal opinion. You can see this in other tools like Perplexity and Google’s AI-integrated search, as well.
The Alignment Debate: Who Decides What's "Right"?
The quest to align AI with human values raises a thorny question: whose values should we use? When tech companies implement alignment techniques, they're making profound choices about what AI systems can and cannot do. It's like having a small group of architects design a city that millions will live in - their choices shape everyone's experience.
Critics point out several concerns. First, there's the issue of centralized control. When organizations like OpenAI, Anthropic, or DeepMind make alignment decisions, they're effectively setting ethical boundaries for AI systems used worldwide. Some argue this concentrates too much power in the hands of a few companies, mostly based in Western countries with specific cultural perspectives.
The creative community has also raised some compelling concerns. Artists, writers, and other creators using AI tools have found that alignment can sometimes limit artistic expression. A well-documented example comes from image generation models, where alignment techniques designed to prevent harmful content can also block legitimate artistic works, especially those dealing with complex themes or depicting the human form. It's reminiscent of how content moderation on social media platforms sometimes incorrectly flags artwork as inappropriate.
Performance trade-offs present another challenge. Research has shown that heavily aligned models sometimes perform worse on creative tasks or specialized technical work. Think of it like a jazz musician who's been taught to follow rules so strictly that they lose their ability to improvise. Some researchers argue that we're sacrificing capability for safety without fully understanding the implications.
However, proponents of strong alignment offer compelling counterarguments. They point out that unaligned AI systems pose serious risks - from generating harmful content to potentially developing objectives that conflict with human welfare. Anthropic's research demonstrates that well-designed alignment techniques can actually improve model performance across many tasks while maintaining safety. It's not unlike how professional standards in fields like medicine or engineering don't restrict progress but rather enable it by creating trust and reliability.
The debate has sparked innovative solutions. Some organizations are exploring democratic approaches to alignment, where diverse communities help shape AI principles. Others are developing flexible alignment frameworks that can adapt to different cultural contexts while maintaining core safety principles. The field is moving toward what we might call "pluralistic alignment" - maintaining essential safety guardrails while allowing for cultural and contextual variation in how AI systems operate.
Future Implications
The alignment of AI systems remains an active area of research and debate. As these systems become more capable and widespread, the conversation around how to ensure they remain beneficial to humanity while respecting diverse values and promoting innovation will only grow more important.
As we develop more powerful AI systems - like the autonomous agents discussed in our previous section - alignment becomes increasingly important. Current research points toward a future where AI systems might help evaluate and align other AI systems, creating what Anthropic researchers call a "virtuous cycle" of improvement.
This doesn't mean we can fully automate ethics - human judgment remains essential. But by creating systematic approaches to alignment, we're building AI systems that can better understand and implement human values. The challenge ahead isn't just making AI more powerful, but ensuring it remains aligned with human interests as its capabilities grow.
Here We Are
Thank you for staying with me through this extended exploration of AI's recent history. These three installments have aimed to provide a foundation for understanding both how we got here and where we might be heading. The rapid pace of development in AI can make it feel like drinking from a firehose, but I hope this historical context helps you better understand and evaluate new developments as they emerge.
This Friday, we'll shift gears to examine a practical application of these technologies. We'll do a deep dive into a recently released tool (it’s a surprise), exploring how it leverages many of the advances we've discussed and what it reveals about the future of AI applications.
And again, if there are specific topics you'd like me to explore or concepts you'd like me to clarify, please don't hesitate to reach out to me at robert@aidecoded.ai.
Further Reading
Open Source and Model Architecture
Foundational Papers
Touvron et al. (2023), LLaMA: Open and Efficient Foundation Language Models
Fedus et al. (2021), Switch Transformers: Scaling to Trillion Parameter Models
Dai et al. (2024), DeepSeekMoE: Towards Ultimate Expert Specialization
Peng et al. (2023), RWKV: Reinventing RNNs for the Transformer Era
Gu et al. (2023), Mamba: Linear-Time Sequence Modeling
Poli et al. (2023), Hyena Hierarchy: Towards Larger Convolutional Language Models
Technical Implementation Resources
Karamcheti & Rush (2023), The Annotated S4 - Detailed explanation of state-space models
The llama.cpp GitHub repository - Reference implementation for efficient inference
LoRA and QLoRA papers (Microsoft, UW) - Key techniques for efficient model fine-tuning
Multimodal AI
Research Papers
OpenAI (2023), GPT-4 Technical Report
Chen et al. (2022), PaLI: A Jointly-Scaled Multilingual Language-Image Model
Zhang et al. (2023), Multimodal Chain-of-Thought Reasoning
Learning Resources
Jay Alammar (2018), The Illustrated Transformer
Google AI Blog: "Introducing Gemini"
DeepMind's Research Blog
AI Agents and Constitutional AI
Key Papers
Park et al. (2023), Generative Agents: Interactive Simulacra
Yao et al. (2023), Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Askell et al. (2022), Constitutional AI: A Framework
Jacob Andreas (2023), Language Models as Agent Models
Practical Implementations
AutoGPT GitHub Repository and Documentation
LangChain's Agent Documentation
Microsoft's Semantic Kernel Framework
Google’s Agents Whitepaper
AI Alignment and Safety
Foundational Papers
Ouyang et al. (2022), Training Language Models to Follow Instructions with Human Feedback
Christiano et al. (2017), Learning from Human Preferences - Seminal work establishing modern preference learning techniques
Ganguli et al. (2022), Red Teaming Language Models to Reduce Harms - Systematic framework for identifying and mitigating potential harms
Glaese et al. (2022), Improving Alignment of Dialogue Agents via Targeted Human Judgments - DeepMind’s Sparrow, a novel approach combining rule-following with factual accuracy requirements
Technical Foundations
Ji et al. (2023), AI Alignment: A Comprehensive Survey - Thorough overview of the field with technical depth
Critical Perspectives
Ngo et al. (2022), The Alignment Problem from a Deep Learning Perspective - Technical analysis of fundamental challenges
Eliezer Yudkowsky (2016), AI Alignment: Why It's Hard, and Where to Start -Influential early discussion of core difficulties
Community Resources and Tools
Development Platforms
Hugging Face Model Hub and Transformers Documentation
EleutherAI's Model Development Guides
Educational Content
Stanford’s CS25 ‘Transformers United’ course
Andrej Karpathy's "State of GPT"