

How Did We Get Here?
The Story of Generative AI’s Rise
A Pivot Point That Changed AI Forever
There's a good chance you've heard the phrase, "Attention Is All You Need", even if you're not an AI researcher. It's remarkable that a scientific paper has achieved this level of common knowledge. A search on the open paper repository, arxiv.org shows 499 computer science papers with "Is All You Need" in the title since the original's submission on June 12, 2017. The paper didn't just have a catchy title. It was a pivotal moment that introduced the Transformer architecture, laying the groundwork for every major generative AI breakthrough we’ve seen since. But how did we get to this point, and why was it such a big deal?
The goal of this newsletter is to explore advancements in artificial intelligence and examine how these innovations are transforming our world through their applications. Before we get started, I thought it would be helpful to establish where we're at. Let’s take a step back and trace the journey of generative AI—from a watershed moment that initially went unnoticed in the mainstream to the transformative technologies shaping our present.
Before Transformers: The Early Days of NLP
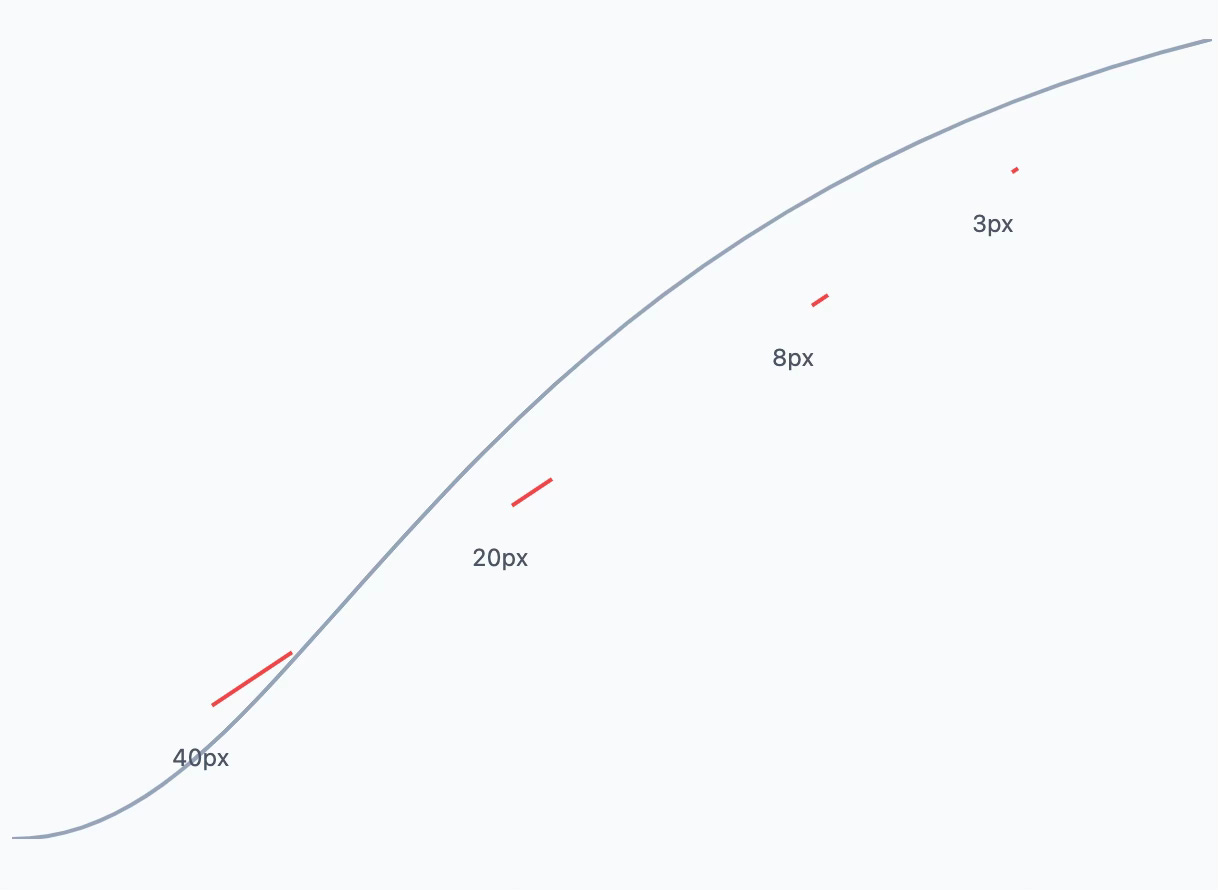
Before the advent of the Transformer, natural language processing (NLP) models leaned heavily on Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks. RNNs are neural networks designed to process sequential data, such as time series or sentences, by maintaining a hidden state that captures information about previous elements in the sequence. LSTM networks improve upon RNNs by introducing mechanisms to better handle sequences and mitigate the problem of vanishing gradients. This issue occurs when gradients—the values used to adjust a model's parameters during training—become exceedingly small, effectively stalling the learning process. Picture trying to climb a hill with steps so tiny they barely move you upward; this illustrates the vanishing gradient problem (see image below). By introducing gates to manage the flow of information, LSTM networks reduced this issue, allowing for better performance. However, these architectures still struggled with modeling very long-range dependencies—imagine trying to summarize a novel while only being able to remember a sentence or two at a time. That fundamental challenge persisted until attention mechanisms revolutionized the field.
The introduction of sequence-to-sequence (Seq2Seq) models with attention mechanisms (Bahdanau et al., 2014) was a game-changer. Attention mechanisms allow models to dynamically focus on the most relevant parts of an input sequence when producing an output. For example, in translation, instead of treating every word in a sentence equally, attention assigns higher importance to words that are more contextually relevant to the word being translated. This is achieved through "attention weights," which highlight key parts of the input, enabling the model to understand and generate outputs with greater precision. By incorporating attention, Seq2Seq models significantly improved tasks like translation and summarization, paving the way for further advancements. However, it was the Transformer architecture’s ability to fully harness attention mechanisms that truly redefined the field.
Key Papers Before 2017:
Bahdanau et al. (2014), Neural Machine Translation by Jointly Learning to Align and Translate: Introduced attention in Seq2Seq models.
Hochreiter & Schmidhuber (1997), Long Short-Term Memory: Pioneered LSTM networks, the backbone of many early NLP systems.
The Transformer Era Begins: “Attention Is All You Need” (2017)
In 2017, eight researchers at Google unleashed the Transformer architecture, a groundbreaking innovation that revolutionized AI by relying entirely on attention mechanisms. Unlike Seq2Seq models, which use recurrent connections that process inputs sequentially, Transformers use self-attention to process all elements of an input sequence simultaneously. This design allows for significant parallelization during training, enabling faster computation and more efficient utilization of hardware resources. In Seq2Seq models, information is passed step-by-step, which can create bottlenecks, especially with long sequences. Transformers eliminate this inefficiency by calculating attention weights across the entire input at once.
Attention mechanisms themselves work by assigning a weight to each part of the input sequence, allowing the model to focus dynamically on the most relevant tokens while generating an output. This not only improves the handling of long-range dependencies, such as understanding the relationship between words far apart in a sentence, but also enhances interpretability, as attention weights provide a visualizable map of what the model prioritizes.
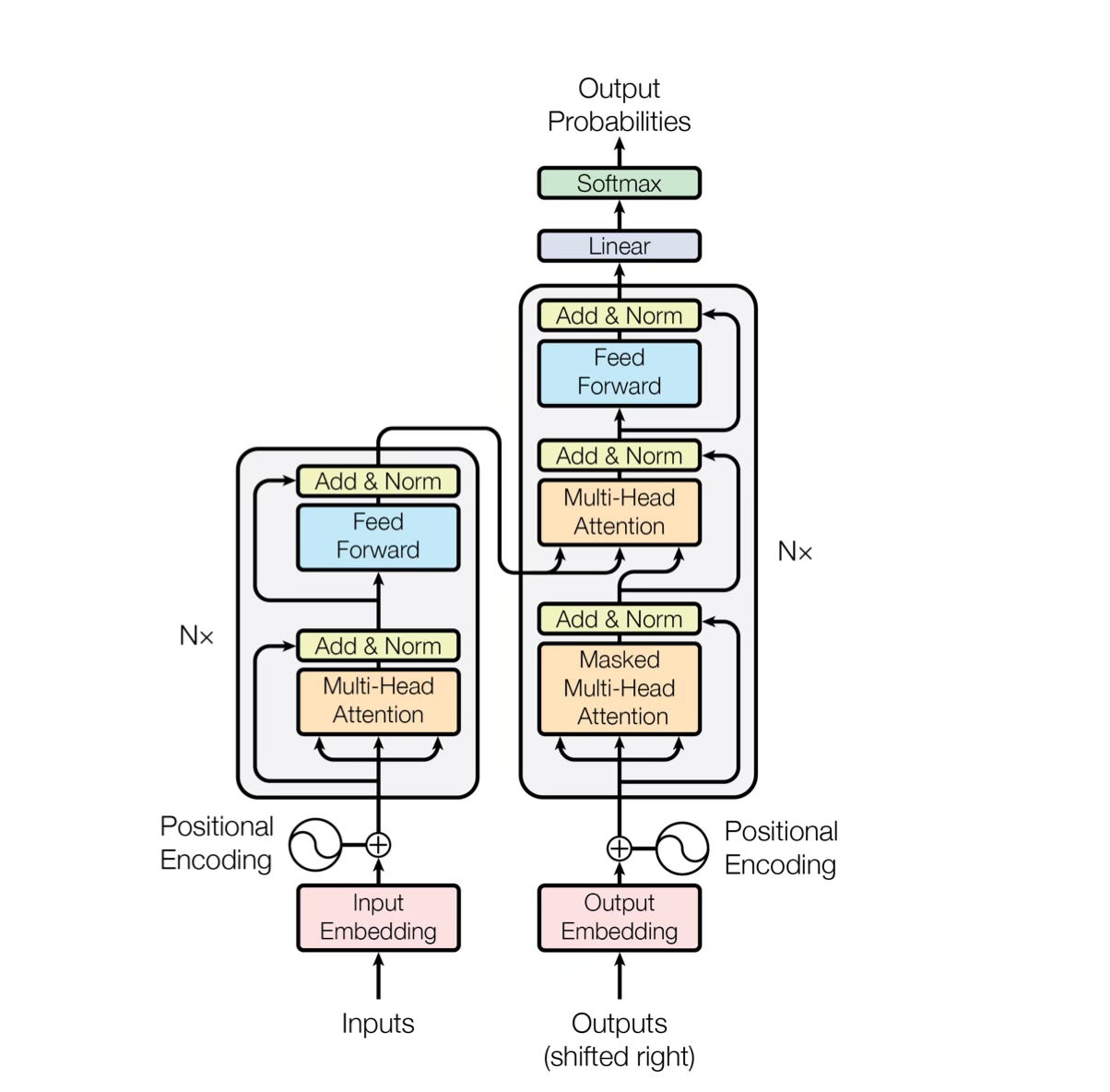
The introduction of the first Transformer model was a pivotal moment in AI research—suddenly, the challenge of handling long-range dependencies was solved. Transformers could efficiently process large volumes of text, retain key information, and generate coherent, creative content. This innovation paved the way for what we now recognize as Generative AI. The concept of self-attention not only improved the performance of language models but also inspired a wave of research into other attention-based architectures, leading to rapid advancements in natural language understanding and generation.
Paper
The Rise of Language Transformers (2018–2020)
Generative Pre-Training: GPT and GPT-2
OpenAI’s GPT series kicked off in 2018 with the paper 'Improving Language Understanding by Generative Pre-Training.' This work introduced a two-stage training process:
An unsupervised pre-training stage, where the model learned contextual representations by predicting the next word in vast unlabeled text corpora.
A supervised fine-tuning stage, where the model was tailored to specific tasks using labeled data.
This two-step approach unlocked the potential of transfer learning in NLP, a concept akin to teaching a student the basics of a subject before asking them to tackle specific problems. In the unsupervised stage, the model builds a broad, foundational understanding by predicting the next word across a diverse range of unlabeled text. This is like learning a language by reading a vast library of books. In the supervised fine-tuning stage, the model hones its skills for specific tasks. During the fine-tuning phase, most of the model’s weights are preserved while only certain layers are adjusted. This is similar to how a person learning a new subject builds upon their existing knowledge rather than starting from scratch. To extend the analogy, it's like a student who has read widely about many subjects (pre-training) then focusing on learning specific terminology and frameworks for a particular field (fine-tuning). The implications of transfer learning are profound: it allows a single pre-trained model to generalize effectively to numerous tasks, reducing the reliance on large labeled datasets for every new application. Transfer learning can sometimes enable models to perform well with just dozens or hundreds of labeled examples, whereas training from scratch might require millions. This versatility and efficiency have been pivotal in advancing the field of NLP.
In 2019, 'Language Models are Unsupervised Multitask Learners' built on this foundation, showing that the sheer size and diversity of the training dataset enabled GPT-2 to learn multiple tasks simultaneously without task-specific fine-tuning. Remarkably, GPT-2 could generate coherent text, summarize content, and even translate languages—all emergent abilities stemming from its exposure to diverse data. This scaling approach revealed a key insight: as models grow in size and their training datasets increase in diversity, they can generalize across a wide array of tasks without direct supervision. It’s important to note that the Transformer architecture, and its ability to leverage this scale effectively, is key to this actually working. The transformer architecture's attention mechanism was crucial in enabling the model to make use of its increased capacity and broader training data.
This scaling phenomenon is governed by mathematical 'scaling laws,' which reveal predictable power-law relationships between a model's size, training data, compute resources, and performance. As models grow larger and train on more diverse datasets, they not only become more capable at existing tasks but also develop unexpected abilities that weren't explicitly trained for. These emergent behaviors – from reasoning to coding to creative writing – suggest that scaling isn't merely about improving efficiency, but about fundamentally changing how AI systems learn and generalize. This understanding has sparked systematic research into the nature of AI capabilities, raising profound questions about the relationship between scale and intelligence, while simultaneously driving substantial investments in computational infrastructure to support ever-larger models.
Papers:
Radford et al. (2018), Improving Language Understanding by Generative Pre-Training.
Radford et al. (2019), Language Models are Unsupervised Multitask Learners.
Understanding Context: BERT
In 2018, Google's BERT model introduced a novel bidirectional Transformer encoder that revolutionized how AI systems process language. Unlike previous approaches that either processed text directionally or combined separate analyses of each direction, BERT developed unified contextual understanding by considering all words simultaneously. This was achieved through masked language modeling, where the model learns to predict hidden words using context from both directions, enabling a richer and more nuanced understanding of language.
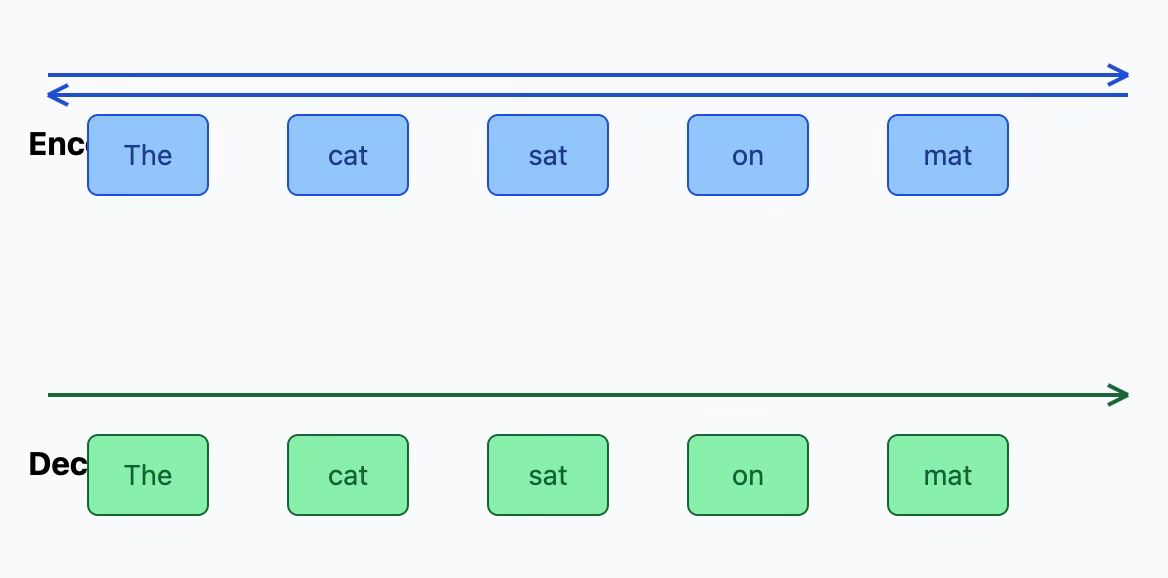
Unlike decoder models, which excel at generative tasks by predicting what comes next in a sequence, encoder models like BERT specialize in developing deep contextual representations of input text. This architectural choice made BERT particularly powerful for tasks requiring comprehensive language understanding, such as classification, question answering, and information retrieval. The success of BERT's approach demonstrated how different architectural designs could be optimized for specific types of language tasks, helping establish distinct families of models within the AI landscape.
Paper
The Era of Large-Scale Models (2020–2021)
GPT-3: Scaling Up
OpenAI's GPT-3 marked a watershed moment in 2020. With 175 billion parameters, it demonstrated how scaling up language models could unlock remarkable new capabilities. Most notably, it showed powerful in-context learning abilities, where the model could understand and execute tasks simply by seeing examples in its input prompt, without any fine-tuning or gradient updates. This flexibility meant a single model could tackle diverse tasks with minimal setup, simply by providing appropriate examples in the prompt.
The engineering achievements behind GPT-3 were equally significant. Despite its unprecedented size, the model maintained computational efficiency through careful optimization of its attention mechanisms and overall architecture. This efficient scaling enabled the model to process longer sequences and handle more complex tasks while remaining practically deployable.
GPT-3 demonstrated three increasingly sophisticated learning scenarios:
Zero-shot learning: Performing tasks with just a natural language instruction, without any examples
One-shot learning: Learning from a single example to understand and replicate patterns
Few-shot learning: Using several examples to grasp more complex patterns and nuances
These capabilities revealed how large language models could not only absorb knowledge from their training data but also apply it flexibly to new situations. Perhaps most importantly, GPT-3's success provided concrete evidence that scaling up model size and training data could unlock emergent abilities – capabilities that weren't explicitly trained for but arose naturally from the model's increased capacity and exposure to diverse data. This insight has profoundly influenced both research directions and industrial investment in AI development.
Paper:
Multi-Modal Extensions
While language models had made remarkable progress in understanding and generating text, the world of human experience encompasses far more than written words. The next frontier in AI development was to create models that could understand and work with multiple forms of information – particularly the vital combination of text and images that humans process so naturally. This expansion toward multimodal AI marked the beginning of a broader revolution in generative AI, where models would learn not just to understand different types of media, but to create them in increasingly sophisticated ways. Two papers in 2021 marked crucial early steps in this direction, demonstrating how principles developed for language models could be adapted to handle visual information, while also laying the groundwork for future innovations in image generation.
CLIP (2021) represented a breakthrough in connecting vision and language understanding. Rather than training models to recognize specific image categories, CLIP learned to understand the relationship between images and natural language descriptions. This was achieved through contrastive learning, where the model learned to match images with their corresponding text descriptions from a large dataset of image-caption pairs. The result was remarkably flexible: CLIP could classify images into any category simply by comparing them to text descriptions, without needing specialized training data for each new task. For instance, if you wanted CLIP to identify pictures of zebras, you wouldn't need a dataset of zebra images – you'd simply provide the word "zebra" and let CLIP match images to that description.
DALL·E (2021) took this visual-language connection a step further by generating images from text descriptions. The key insight was treating images as sequences of tokens, similar to how language models process words. Just as GPT models learn to predict the next word in a sequence, DALL·E learned to predict the visual tokens that would create an image matching a given text description. This required solving several technical challenges, including developing an efficient way to compress images into tokens and training a Transformer model to handle the much longer sequences that result from tokenized images. DALL·E demonstrated that the principles underlying large language models could extend beyond text, opening new possibilities for AI-powered creative tools.

Together, these models showed how the Transformer architecture could be adapted for multimodal tasks, laying the groundwork for more sophisticated AI systems that could seamlessly work with both text and images.
Papers:
Diffusion Models and Image Generation (2021–2022)
While Transformers dominated NLP, diffusion models emerged as a powerful new force in image generation by approaching the problem from a fundamentally different angle.
DDPM introduced an elegant solution inspired by thermodynamics: instead of trying to generate images directly, the model learns to reverse the process of gradually adding noise to images. During training, the model observes images as they transform from clear to increasingly noisy states, learning the patterns of how structure breaks down into randomness. Then, for generation, it applies this knowledge in reverse – starting with pure noise and gradually refining it into a coherent image, much like watching a photograph slowly emerge in a darkroom developing tray.
The key insight comes from a physical process called "diffusion" (which is where these models get their name) and a fundamental principle in thermodynamics called the "second law of thermodynamics." In thermodynamics, systems naturally tend to move from ordered to disordered states - think about how a drop of ink naturally spreads out (diffuses) in water, or how heat flows from hot regions to cold ones until everything reaches the same temperature. This process of moving from order to disorder is essentially irreversible without adding energy to the system.
The brilliant insight of diffusion models is that they mathematically formalize this process and then learn to reverse it. Here's how the parallel works:
In thermodynamics:
A system naturally moves from ordered states (like a clear image) to disordered states (like random noise)
This process follows well-understood mathematical principles
The process is gradual and predictable
Reversing it requires energy and precise control
In diffusion models:
Training images are gradually corrupted with noise, following a carefully designed schedule
This forward process is mathematically defined to be similar to natural diffusion
The model learns to estimate and reverse each tiny step of this noise-adding process
During generation, the model provides the "energy" to reverse the disorder, step by step
The mathematical framework used in diffusion models (specifically, the forward process) is directly inspired by the Langevin dynamics and the Fokker-Planck equation from statistical physics, which describe how particles diffuse through space over time.
This iterative denoising process addressed key challenges that had plagued earlier approaches like GANs (Generative Adversarial Networks). Where GANs attempted to generate images in a single step – leading to issues like mode collapse where the model would get stuck generating a limited variety of images – diffusion models took a more measured approach. By breaking image generation into hundreds of small denoising steps, the model gained unprecedented control over the generation process. Each step only needed to remove a tiny amount of noise, making the overall task more manageable and leading to higher quality results.
The success of DDPMs marked a crucial shift in how we approach image generation. Their probabilistic framework provided both mathematical elegance and practical benefits: more stable training, better image diversity, and fewer visual artifacts. These advantages would soon make diffusion models the foundation for groundbreaking applications like DALL·E 2 and Stable Diffusion, setting new standards for generating photorealistic images.
Stable Diffusion helped usher in AI democratization when Stability AI made the decision to open-source their state-of-the-art text-to-image model. While the underlying diffusion process remained similar to DDPM, Stable Diffusion introduced important technical innovations that made it practical for widespread use. Most notably, it performed the diffusion process in a compressed "latent space" rather than on full-sized images, dramatically reducing the computational resources needed for generation. This meant that, for the first time, high-quality AI image generation could run on consumer-grade hardware rather than requiring expensive GPU clusters.
To conceptualize the meaning of “latent space diffusion”, first think about how much information is actually needed to describe an image meaningfully. While an image might be stored as millions of individual pixels, much of that data is redundant or not essential to understanding what the image represents. For instance, if I show you a picture of a cat, your brain doesn't process every single pixel - it captures the important features like the shape of the ears, the texture of the fur, and the overall pose.
This is where latent space comes in. The term "latent" means hidden or underlying, and a latent space is essentially a compressed representation that captures the fundamental features of something while discarding unnecessary details. Think of it like a highly efficient shorthand for describing images.
Stable Diffusion uses what's called a variational autoencoder (VAE) to create this efficient representation. The VAE first learns to compress images into this latent space. If a standard image might be 1024x1024 pixels (over a million numbers), its latent representation might be just 64x64 (about four thousand numbers). This compression preserves the important features while discarding redundant information. It's similar to how a skilled artist can capture the essence of a scene with just a few well-placed brush strokes rather than painting every detail.
Now, instead of running the diffusion process on the full-sized image (which would be computationally expensive), Stable Diffusion performs the diffusion in this compressed latent space. It's like planning a painting by sketching with broad strokes before adding fine details. The model learns to denoise these compressed representations, which requires far less computational power than working with full-sized images.
When it's time to generate the final image, the VAE's decoder converts the cleaned-up latent representation back into a full-sized image, adding back appropriate fine details in the process. This is similar to how an artist might start with a rough sketch and then gradually refine it into a detailed painting.
This innovation was what helped enable the democratization of AI image generation. Without it, running these models would require expensive hardware beyond the reach of most users. With latent space diffusion, even a modest consumer GPU can generate high-quality images in seconds.
This accessibility, combined with the decision to open-source the model, sparked a wave of community-driven innovation. Developers and researchers worldwide could now not only use the model but also experiment with it, modify it, and adapt it for new purposes. The impact was immediate and far-reaching: artists integrated it into their creative workflows, developers built user-friendly interfaces and plugins, and researchers used it as a foundation for pushing the boundaries of what AI could create.
The open-source nature of Stable Diffusion created a virtuous cycle of innovation: as more people worked with the model, they discovered new techniques for fine-tuning it to specific artistic styles, improving image quality, and reducing unwanted biases in the generated content. These improvements were shared back with the community, leading to a rapidly evolving ecosystem of tools and techniques. This collaborative approach demonstrated the power of open-source development in AI, showing how shared knowledge and collective effort could accelerate progress far beyond what any single organization might achieve alone.
Papers:
Large Language Models Get Chatty (2022–2023)
ChatGPT: Conversations Made Easy
In late 2022, OpenAI's launch of ChatGPT marked an evolution in AI development by addressing a fundamental challenge: while large language models like GPT-3 possessed remarkable capabilities, they weren't naturally inclined to be helpful, truthful, or safe in their interactions with humans. ChatGPT tackled this challenge through Reinforcement Learning from Human Feedback (RLHF), a technique that changed how we align AI systems with human values and preferences.
RLHF represented a shift from traditional training approaches. Instead of just learning patterns from data, the model learned from human judgments about what constitutes good or helpful behavior. This process worked in three stages:
First, human trainers demonstrated desired responses to various prompts, creating a dataset of preferred behaviors.
Next, these examples were used to train a reward model that could evaluate responses based on their alignment with human preferences.
Finally, the language model was fine-tuned using reinforcement learning, gradually adjusting its behavior to maximize these human-aligned rewards.
This approach helped create an AI system that was powerful and more reliable, helpful, and attuned to human needs.
The transformation of a raw language model into ChatGPT required solving numerous practical challenges beyond RLHF. Engineers had to develop systems for maintaining coherent conversations over multiple turns, handle edge cases where the model might produce inappropriate responses, and scale the infrastructure to support millions of simultaneous users. These technical achievements were important and, in my opinion, a bit under appreciated in bridging the gap between laboratory AI and practical applications.
ChatGPT's release proved transformative for public perception of AI technology. By providing an intuitive interface to advanced AI capabilities, it demonstrated the practical value of language models in everyday tasks – from writing and analysis to coding and creative work. This accessibility sparked widespread adoption beyond the traditional technical audience, integrating AI into daily workflows across professions and disciplines. Moreover, ChatGPT's launch catalyzed broader societal discussions about AI's potential impact, raising important questions about education, workplace automation, and the future relationship between humans and AI systems.
If you’re reading this newsletter, I’d be shocked if you haven’t used it yourself.
What’s Next?
I had initially planned on introducing some further advancements in this space to bring us closer to the present, but I don’t want the length to be too overwhelming. Instead, there will be a part 2 of this “Generative AI history” lesson coming in a follow-up.
After that, I’ll begin writing up breakdowns of more recent papers and advancements on Tuesdays, discuss applications and products on Fridays, and periodically perform demos, discuss industry trends, and provide other AI miscellany at more random intervals.
As a note, I could have included many other papers in this Part 1, but tried to select what I thought were the most representative papers in advancing the field over the period of 2017-2023. If there are others that you would have liked to have seen included, drop me a line and let me know.
Thanks for reading, and if you haven’t yet, I’d love for you to subscribe.
Wow, this summary is awesome! The tech evolution has been so fast, and it’s great to have a recap of the key moments that got us here. I really enjoyed this!